

Part III: Making Machine Learning Happen
In the previous two parts, we covered the ground of the benefits of machine learning and how to stand up a development test environment using one of the available open source stacks. In this part, we get real, with a real world application. In spite of its relative approachability, this is a complex project. At the end of it you will find links to my GitHub repo with all the components you’ll see here, including our Vagrant files with a bootstrap.sh that includes all relevant installations. If you missed the previous versions you can access Part I - Collect Everything via Integration and Part II - Building an Elasticsearch Test Environment.
Apache Mahout
We saved the installation of these for this article. Mahout is a project that allows us to produce the kind of machine learning algorithms we need to take our Elasticsearch data to the next level.
In our VM SSH, we’ll need to undertake the following actions:
- Make sure we’re running the latest version of Maven, to make our build process easier. This is not as easy with Maven 3.3.x as it would be earlier versions, but this link gives us the best means with the version of Ubuntu we’re running.
- Install Apache Hadoop, to take care of our dependencies in Mahout.
- Finally, install Apache Mahout.
We will use Mahout to use the Log Likelihood Ratio (LLR) method for determining which items co-occur at intervals, and subsequently, which concurrences we can use to indicate preference.
Create Our Index
The first step is to create our index. We can do this via CURL:
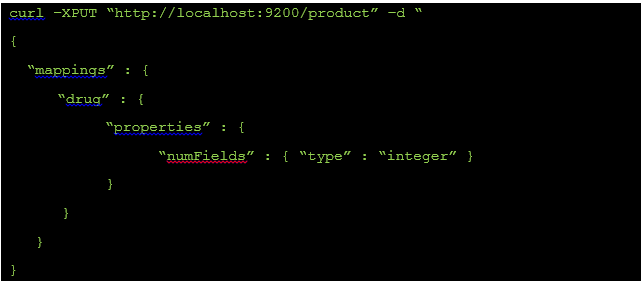
OR we can do this via our Sense application: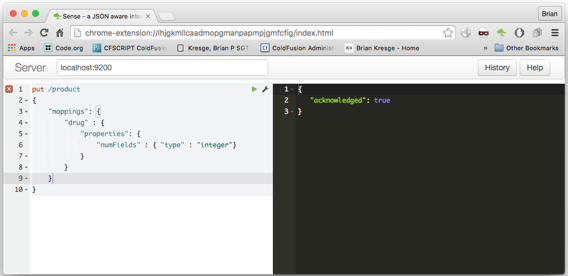
Get Our Product Data From X3 and into Elastic
Using Denise Hartman from RKL eSolutions excellent series on X3 Web Services, you can create two web services for consumption by a queued process.
In this case, I’ve set up two services that give us item data for our Elasticsearch indexes and a list of products ordered with total quantity sold on a given day for a limited date range. For the purposes of this example, I’ve limited both outputs to around 1000 records.
The next step is to take this XML and convert the first set, our drug product data, to a meaningful setup for our Elastic index. I won’t bore you with the conversion (you can use Node.js with xml2json). I have conveniently created the bulk-create Elasticsearch JSON file, which you can download here.
Your entries should look like this:

Each set of lines will create the document and identify the fields in the document. The bulk API behind Elastic lets you perform a whole host of index operations in an individual call, a real boon for indexing speed!
This one is better done with curl.
curl –s –XPOST http://localhost:9200/_bulk –data-binary @product.json; echo
Once we do this, we can test our search API against a drug name.
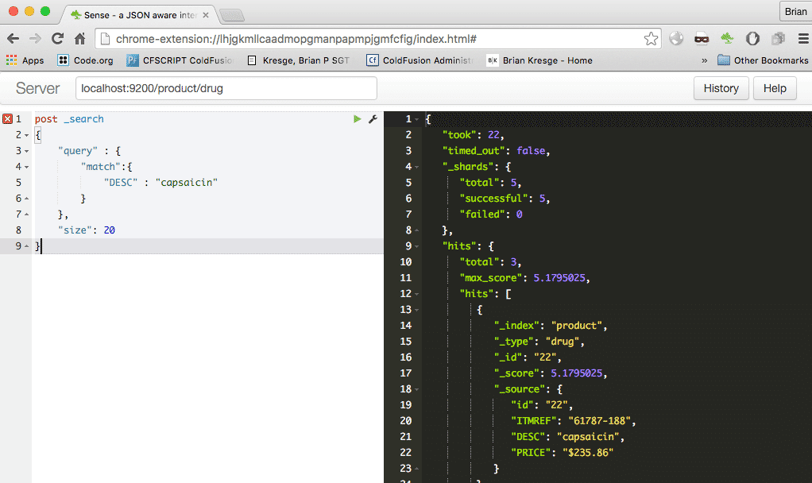
This by itself is an incredibly speedy search engine API that you could introduce on a website or for other purposes! This system has some serious fuzzy search and matching capabilities that are worth the time to research on your own.
Creating our Mahout Item Similarity Job
The next step is to take the tab delimited file that we’ve generated out of our Item ID and quantity ordered per day data set.
Our command, run with the file locally on our Vagrant SSH (which you can get to with the vagrant ssh command), looks like this:

This, in turn, generates an output that determines co-occurrences as a means to determine indicators of product preference. This is determined by using --similarityClassname SIMILARITY_LOGLIKELIHOOD in our command line. Lines should look like this:

Add Indicators to Product Documents in Elasticsearch
Now that we have this data from Mahout, we must put these in the drug listings in Elasticsearch. We have to do, then, some work with the part-r-00000 file that we find in our designated output file.
Since I don’t have Node.js running on the Vagrant VM, I have a little Python script that I will use to create the bulk update JSON we need out of this file. We can then perform searches matching our indicators once we bulk update our documents in Elasticsearch.
Here’s what that looks like (also in our GitHub here):
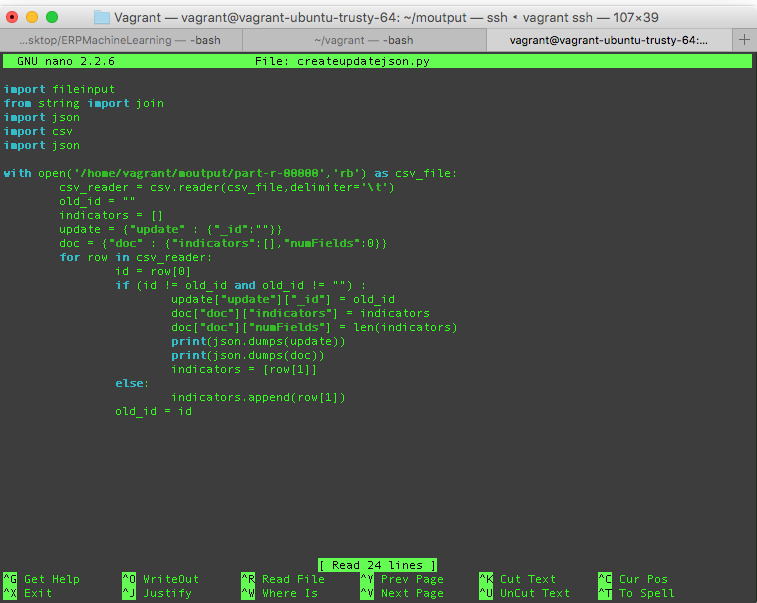
We run this there from the Vagrant VM command line:
![]()
The file should look like:

Now, we take that output file back to our normal environment, and do our bulk update again using curl.
![]()
Now, we have what we need for a basic recommendation engine!
Creating our Recommendation Service
Node.js lets us rapidly stand up a web server, and has a wonderful Node.JS client. In your node instance, you can simply run npm install elasticsearch to install the requisite client.
Here’s what our server looks like (also available here):
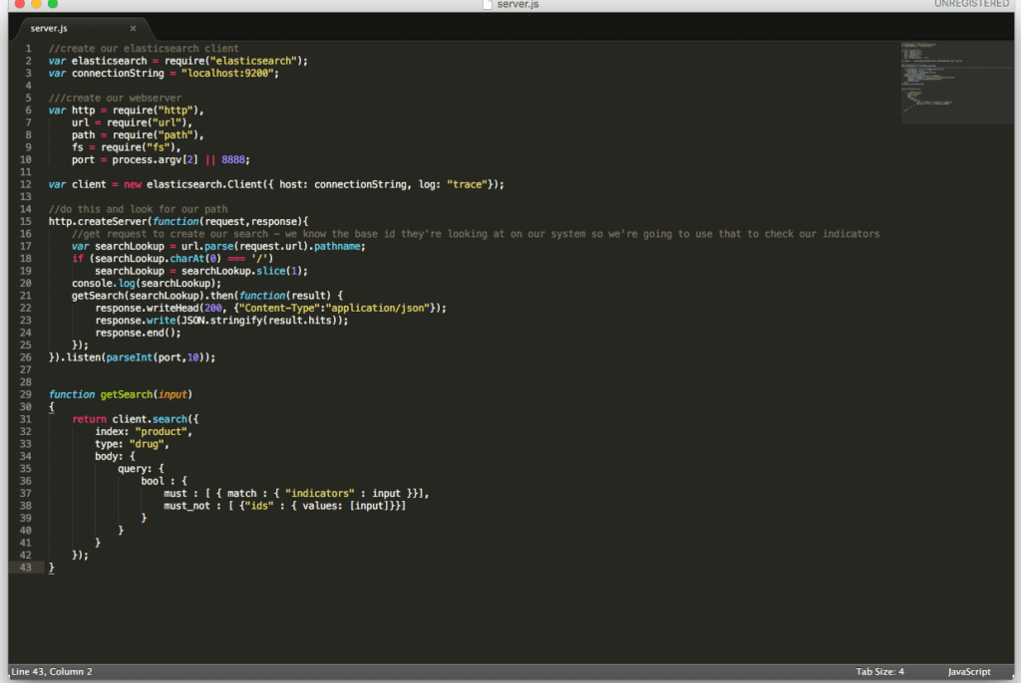
In the code, we also have trace logging enabled on the client, so that we can get feedback of what our search looks like in the console. What we’re doing here with this recommender system is looking for drugs with indicators equal to what we put in, but explicitly not looking up ones we do have.
This basically creates a tiny web server that searches Elasticsearch for drugs that match our established indicators locally on port 8888.
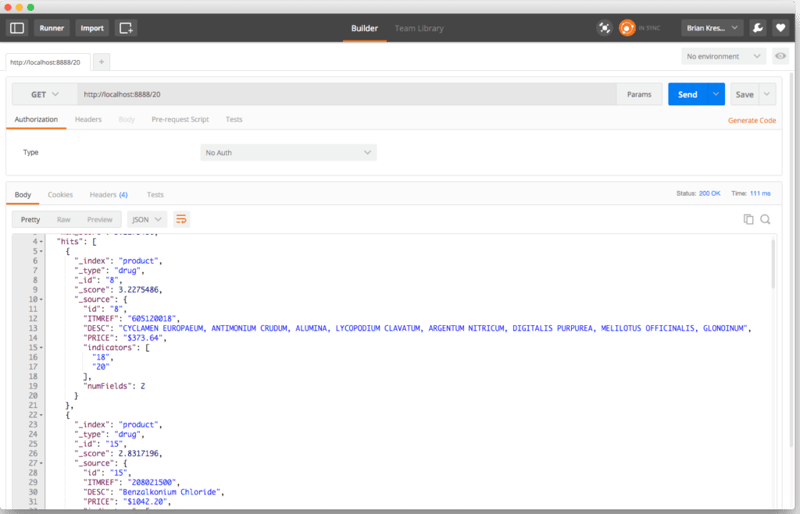
Here it is realized with a response:
Where to go from here?
As you can see, there is vast potential to revise your indicators and mine your data for increased relevance in recommending products based on sales.
Elasticsearch is an amazing product with great client hooks for all the major development stacks. It’s relatively painless to set up and deploy.
Mahout is a rapidly evolving product that constantly amazes with its ability to produce useful algorithms.
Your Sage ERP investment gives you a lot of data, and a combination of these newer technologies really allow a small- or medium-sized business to approach the kind of Machine Learning that has long been the province of the “big boys.” Get that data out and to work for you!
The GitHub link for this project is here. Feel free to pull down and play around!
Contact RKL eSolutions should you have any more questions regarding Harnessing the Power of your ERP for Machine Learning.

